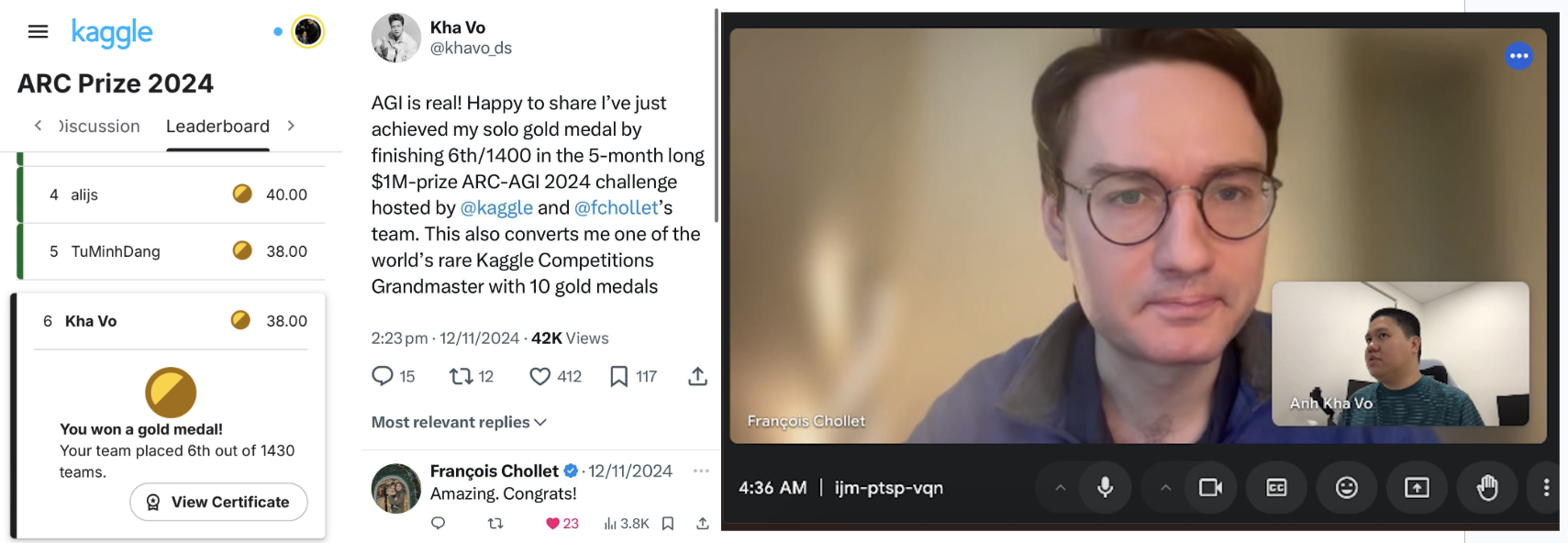
(Rank 6/1637) Finetune LLMs to solve the famous abstract reasoning challenge with Unsloth AI...
by Kha Vo
ARC Prize (Abstract Reasoning Challenge) on Kaggle has always been one of the most (if not the most) difficult AI challenge nowadays that even OpenAI o3 pro struggles!
For the ARC Prize 2024 edition, which lasted for 6 MONTHS (yes you read it right), I original finished at SIXTH place out of roughly 1400 teams!
Because of this painstaking achievement, I was contacted by and then privately met with Francois Chollet, one of TIME’s top 100 most influential persons in AI in 2024!, to share about my solution and approach! We also talked about a possibility that whether I can work for his start-up (but for some undisclosed reason I didn’t end up working for him). For some reason, I was finally removed from the Kaggle leaderboard (read the last part of this post to understand why).
No one has ever thought of using LLMs in this competition, especially given the context that the previous edition (2019) of this Kaggle challenge has seen ALL of the top 10 solutions being program synthesis or brute-force style approaches.
My idea of using LLMs to predict the output grid DIRECTLY from the input grid is, IMHO, really BOLD. But… I am not the only person who thought of this! The top 3 solutions also used this approach.
So,… that’s why we all occupied top places in the LB.
Before going into my solution, let’s take a brief look at the problem statement for this challenge.
For this competition, we are given a train dataset of 800 ‘tasks’. For each task, we will have a few (from 2 to 5) pairs of ‘train’ input-output images, and a few (from 1 to 3) pairs of ‘test’ input images. It’s hard to explain so let me plot a few tasks.

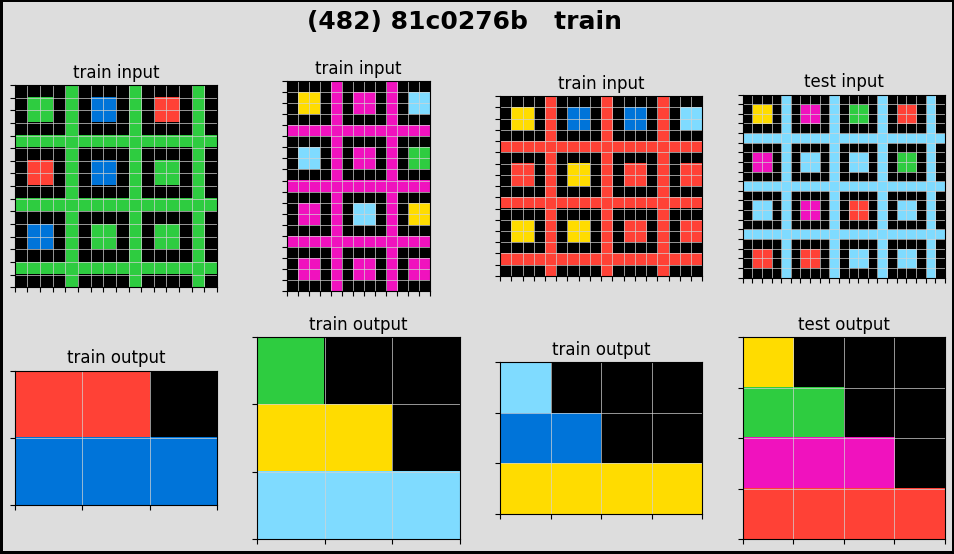
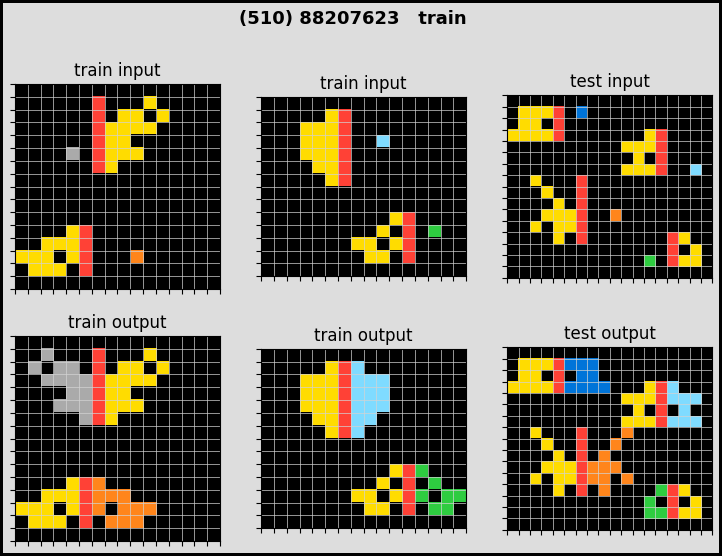
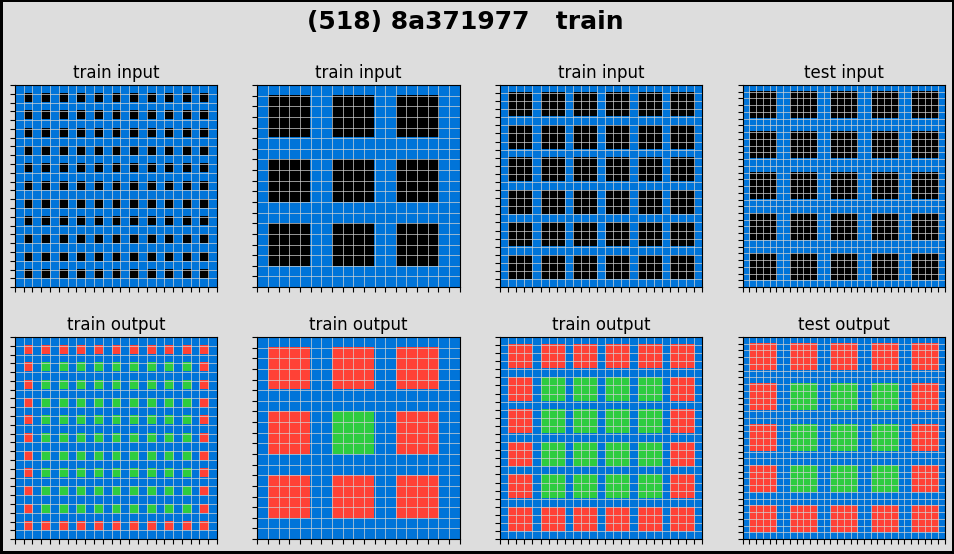
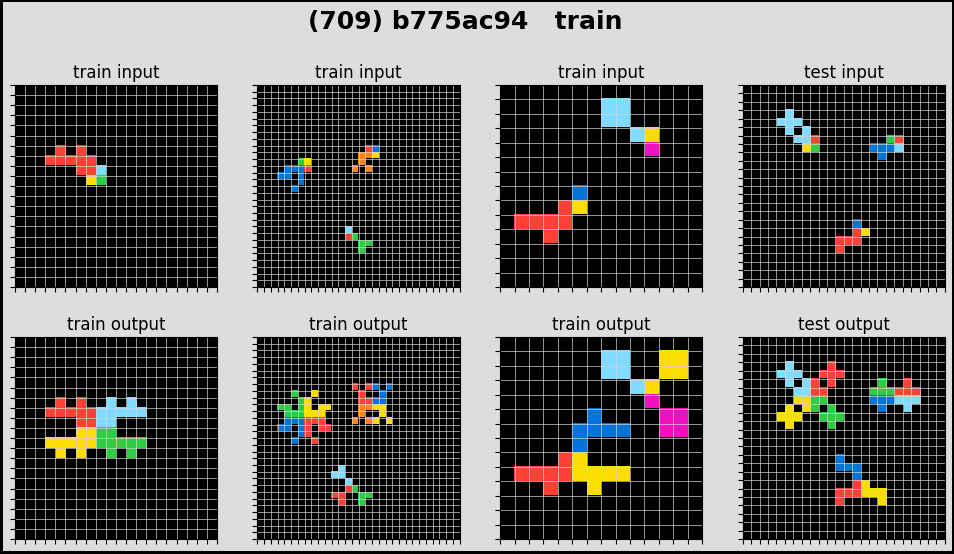
As you can see, for each task, there is an ‘abstract reasoning’ rule that transform an input into an output. For normal humans, we can quickly grasp how the inputs are transformed into the outputs (for each task). However for the machine, it is of near impossibility to conceive these simple but non-textual abstraction.
So, given these 800 training tasks, our main goal is to develop an AI model/system, that can perform on these types of tasks. The most difficult part about this contest is that, the model will need to perform on UNSEEN HIDDEN tasks that it has never seen before! And the types / natures of these hidden tasks are of complete difference than the training tasks! Well, how can you tell the AI to understand a new abstract movements such as “fill in the hole” or “combine some objects to make a square”, if they have never seen them before. So that’s why we have this competition. Let’s have a look at some ‘hidden’ test tasks (that were actually kept as secrets for the whole ARC 2024 competition and were only recently released in 2025 as the additional training data for ARC 2025 competition which is ongoing).

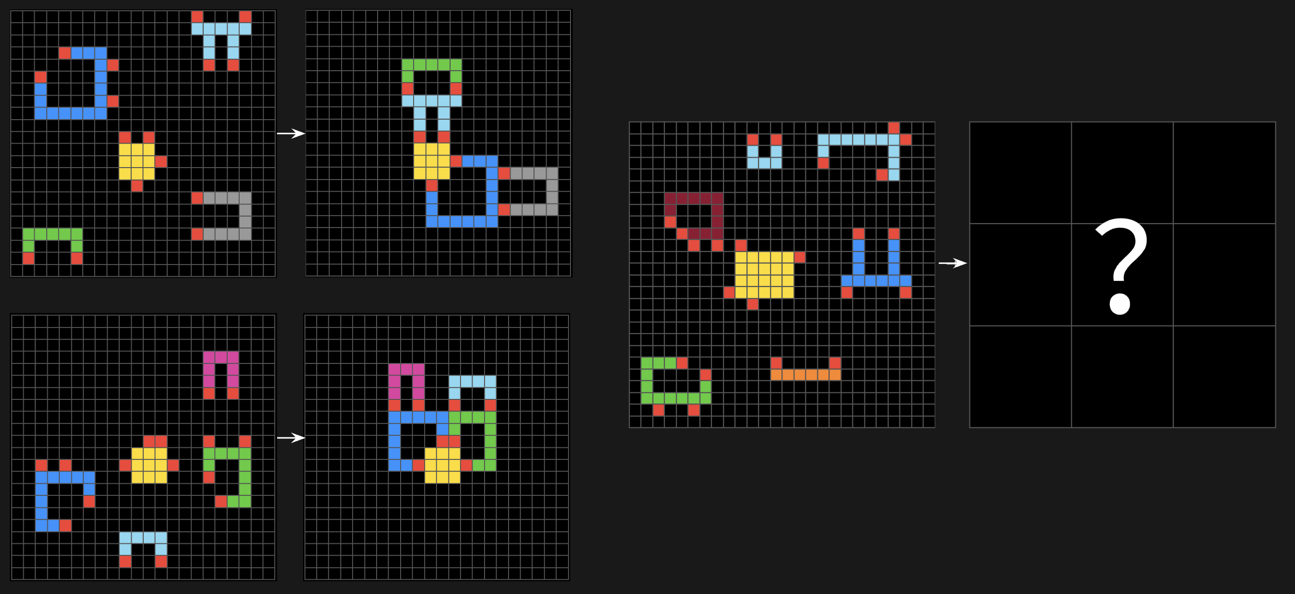

For viewing the full training tasks for ARC Prize 2025, I have compiled a nice-looking public Kaggle notebook here.
Even SOTA reasoning models like OpenAI o3-pro, Claude, or anything (up until the point of this writing), the performance is under 5%, which is crazy, but understandable. We can’t expect LLMs models which were trained on text data to perform on vision data. However, the previous statement is not completely true. For SOTA vision models, they still can’t perform on these tasks! The ARC Prize Foundation continually updates their benchmark tests on new SOTA models anytime they’re released. And this is the result:

So, with this kind of really challenging contest, how did I approach the problem?
Let’s get to the main part: my solution. There are a few main parts:
1) Formulate the problem into a form that allows LLMs to solve
Basically, I want to DIRECTLY ASK the LLM the following question:
question = """
Try solving this introductory Abstraction and Reasoning Challenge (ARC) task.
You are given several example input–output grid pairs that illustrate the underlying transformation. Your goal is to infer the rule that maps each input grid to its corresponding output grid, and then apply that rule to the test input grid.
All transformations adhere to the standard ARC priors: objectness, goal-directed behavior, numerical reasoning and counting, and basic geometric and topological principles.
Your task is to generate an output grid for the test input that is consistent with the distribution and patterns observed in the training input–output pairs.
Training input–output pairs:
#insert train input-output pairs
Test input images:
#insert test input images
"""
The tricky part is that how can it understand the spacial abstract meaning of objects inside the grids which are also texts in the question?
The answer is that we can modify the tokenizer to let it understand pixels! If we use the default tokenizer as is, there’s no way it can understand that ‘[[1, 1, 1], [2, 2, 2]]’ is an object with three pixels of color ‘1’ and three pixels of color ‘2’. As a result, ‘1’, ‘2’, or even ‘[’, ‘]’ should represent as independent tokens without their original meaning, and must not be merged with any other tokens or with each other. We can do by modifying the tokenizers! The idea is to represent each digit as new independent symbols.
2) Finetune LLMs with unsloth.ai
I happened to find unsloth.ai as the SOTA tool for finetuning LLMs! Previously I used some no-code GUI approaches like H2O LLM Studio, or I finetuned models directly by LORA with original transformers and pytorch support. But after trying unsloth, I have to admit that it is indeed the BEST library to finetune LLM models, because:
-
It makes BOTH training and inference much faster. Unsloth’s ability to significantly speed up (3x) the inference process made a huge difference when we want to run LLM inferencing inside a Kaggle notebook with limited resource (in this case: only 2xP100 GPUs are given to each participant within a 12-hour runtime).
-
It is really easy to use. The most difficult part is to installing and adjust the configurations. But when it comes to the training / inferencing, it is not so much different than a normal deep learning pytorch library. Everything went smoothly.
-
It supports a wide range of models, including LLAMA, Deepseek, Qwen, Mixtral, Phi, Gemma… This allows me to play and find the best suitable model (which is Qwen2.5-0.5B-Instruct).
The dataset for training is not simply the orignal training tasks transformed into questions. LLMs can’t generalize with just about 1000 data samples, which is impossible. So I need to use all of the synthetic datasets (of new tasks) that were released by other competitors during the 2019 edition (as well as new datasets during 2024). But that’s still not sufficient. We need to augment EACH TASK with variants of itself, such as:
flip horizontally / vertically
rotate 0 / 90 / 180 / 270
random color swap
Combining the above operations on each task, we can easily have up to 32 variants of input-output pairs for a single task. That significantly increases the training population and also helps the LLMs generalize, since now for each task we have variants, and they can focus more on diffirentiate the spacial abstract meaning of the objects / movements, rather than just memorizing shapes or colors.
Finetuning LLMs is the HARDEST part of everything else. There were countless hours of errors / debuggings, and frustrating and disappointed nights of model not learning. However, with the nature of trial-and-error of Kaggle competitions that I experienced in the last roughly 10 years, it usually came to a fruitful result. Here are some (dirty) training procedures:
3) Test-time finetuning during inference
When the trained model faces a hidden test task in the inference mode, it will perform a quick re-training JUST FOR THAT TASK. This helps specifically only in this unique competition, because we have various ways to augment the on-hand task (flip, rotate, color swap…).
The tricky part for test-time finetuning is to have all model re-training sessions (100 in total) fit within 12 hours of Kaggle runtime and with limited resources (1xP100 or 2xT4 GPUs). That can be done with asynchronous concurrent processes design:
%%python --procedure train_session_1
training_call(gpu=0)
%%python --bg --procedure train_session_2
training_call(gpu=1)
%%python --bg --procedure infer_session_1
inference_call(gpu=0)
%%python --bg --procedure infer_session_2
inference_call(gpu=1)
proc_exit_codes = await wait_for_subprocesses(train_0, train_1, infer_0, infer_1)
The asyncio-style process design allows me to better log outputs, but it has way more unknown errors (mostly training got freezed without any log produced) than normal multiprocessing Python package.
4) Ensembling with past-solutions and Candidate selection optimization
Some heuristic-based solutions from the 2019 edition were still very strong and helped the ensemble of predictions.
To ensemble different predictions of a single task, I used a unique self-made selection elimination technique that helps to reduce the irrelevant predictions for a single task, by observing various heuristic-based factors of that task: background detection, object count, task type classification. For instance:
-
Detect background color, eliminate predictions with wrong background color.
-
Detect whether the task is of a specific type (such as only_recolor, only_move, always_num_input_objs_equal_num_output_objs, …), then invalidate predictions that are not of that task type.
-
Role swapping: use the prediction (A) as 1 input-output pair for training, and swap it with 1 real train input-output pair (B). Then with a new collection of train input-output pairs, try to predict the output of B and compare it with the real output of B. If they don’t match then the prediction (A) is eliminated.
Remarks
Getting a solo gold in a Kaggle competition is no joke. This competition has consumed all my life and soul in 6 months.
However, if you look at the competition LB by now, you don’t see me there because of the Kaggle buggy procedure when they hand out money prizes. It was a really long and frustrating story. If you want to understand more about this unfortunate incident, that also happened to 3 other teams, please read this Kaggle discussion topic and all of its comments there. You’ll also see me ranting about it there :)
Anyway, that doesn’t reduce the validity of my solution, but as how it turned out, I would like to hold off the sharing of my full code solution for now, to gain an advantage on the ongoing 2025 edition (which is now running from Mar to Nov 2025).
I will post my full solution once ARC Prize 2025 is concluded (Nov 2025).
Thank you for reading.
My code for ARC Prize 2025 can be found here (embedded below):