(Rank 13/832) Finetune an LLM to play the game of '20 questions'
by Kha Vo
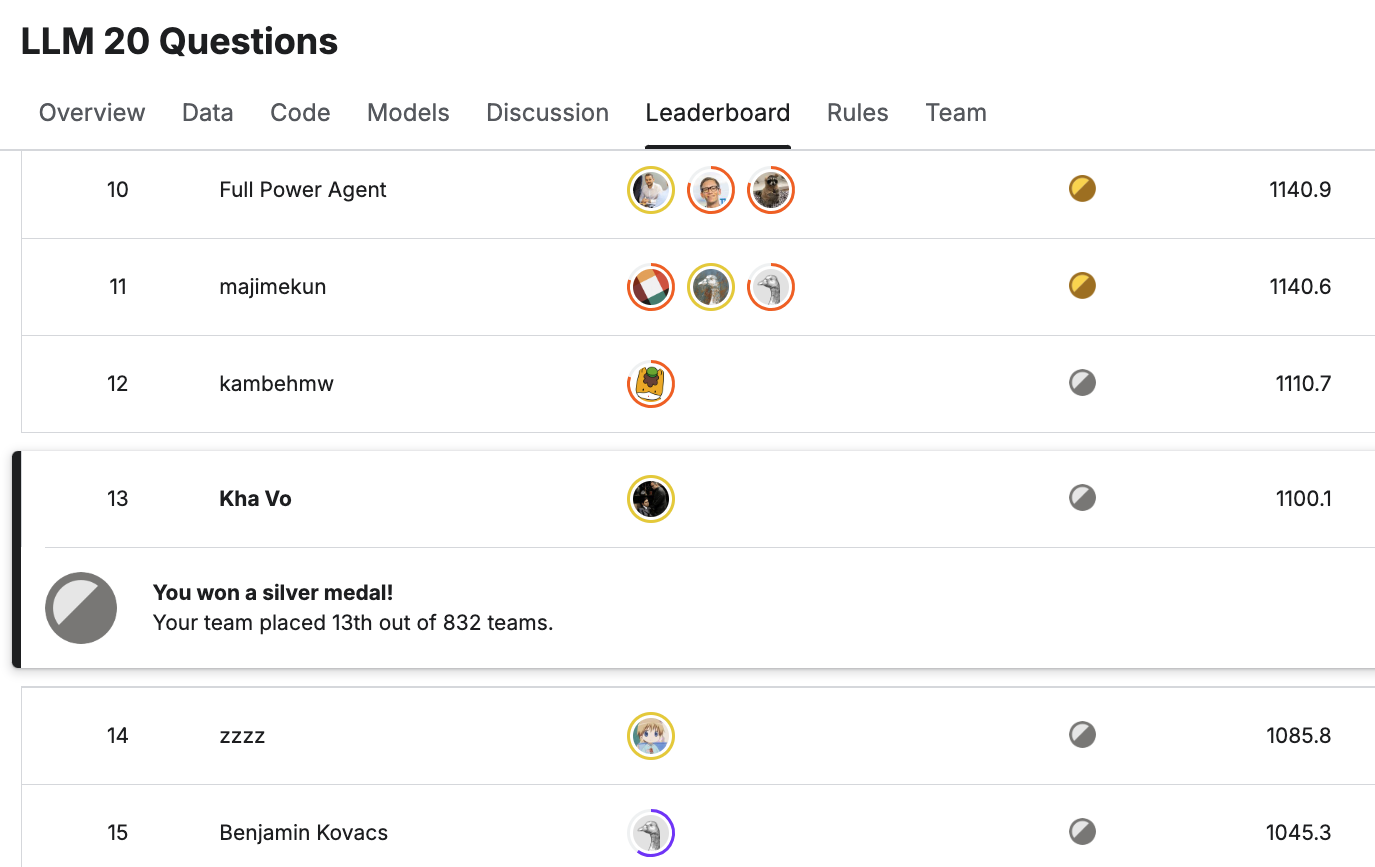
I’ve just earned my top solo silver medal (rank 13) in a Kaggle simulation competition “LLM 20 Questions”, where we need to develop an LLM to play the game of 20 questions.
The great thing about this challenge is that in each match, there are 4 players involved, instead of 2. It is a 2 versus 2 match-up. A team will comprise of 2 players, one acts as the questioner and the other as the answerer.
At the start of the game, a common secret keyword is given to the answerers of the 2 teams. Then the questioner of each team will start to ask its teammate answerer a binary (yes or no) question, receive an answer, and produce a keyword guess.
If the guess of the questioner of any team is correct, 2 players of that team will win the match and rise on the global leaderboard (if both correct in the same turn, so a tie). If both teams are wrong, comes the next turn. This will repeat for 20 questions (20 turns).
A key thing about this competition is that a fixed list of keywords will be embeded to the referee (Kaggle server). This list will change and inaccessible by any means in the final evaluation period (final 2 weeks).
During the competition, I have publicly shared to the Kaggle forum my approach which worked really well in both public and private LB.
I named it as “offline-policy-questioner agent”. It got >50 upvotes and >250 forks!
You can find the code in my [Kaggle notebook]. Enjoy!
The idea is that, public open-weight LLMs are not so skillful in 20 Questions game. Asking broad questions and narrowing down gradually is the only way to find out the secret keyword, but many LLMs seem not to be great in that area.
In my approach, I prepare an offline dataset of hundreds of possible questions and answers to every question-keyword pair. Then we will try to follow the policy of asking based on this offline dataset.
Why it works? That’s because the organizer has confirmed that the current public keyword list is representative to the unseen private list which we don’t have. So the principles of this approach is:
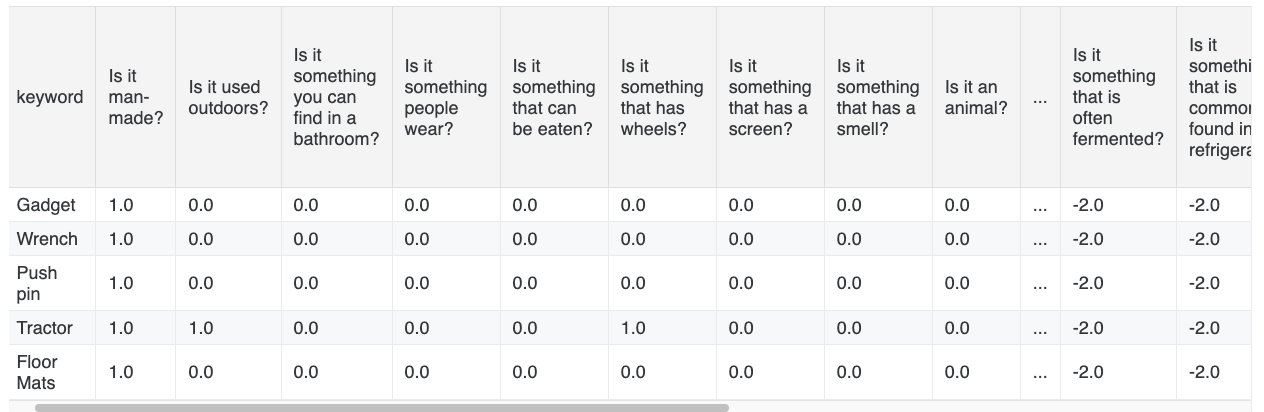
1) Collect hundreds of diverse binary questions that are both broad or narrow that can help us determine the keyword.
2) Use an LLM to find out the answer (yes or no or unsure) to each question-keyword pair. The keyword is drawn from the public keyword list.
3) Use the pre-built knowledge to ask the next question given the history of asked questions and corresponding answers.
4) After each round, with all the question-answer pair, remove the unqualified keywords.
5) Select the next question that has the most entropy split as possible (i.e., 50% yes 50% no) based on the remaining qualified keywords.
6) Unofficially, guess the keyword from the public list, that means use the keywords in the public list just as the proxy to guide the asking policy. That means in each round, we memorize these “unofficial guesses” to prepare for the next best question only.
Officially, use the asked questions and answers to make the LLM predict the real private keyword by itself.
The advantages of offline-policy approach are:
1) it can partly overcome the issue of LLM not being able to play the game properly,
2) it can resolve the issue of word-limit in asking questions, and
3) it can replace the LLM’s questioning responsibility, which is the hardest part in [questioning, answering, guessing].
Another good point is that anybody can submit it right away, as it can work in private leaderboard without no further changes. You can see an example episode below where this bot excellently correctly guessed the keyword in 10 moves.

The successful rate of this bot is about 10%, which means you will win 1 game in about 10 games played! This is considered a high percentage given the difficulty of the game.
In my own version of this bot, I have many more features that I want for my own. My version can reach >900 points on the LB recently (but it got deactivated when I submitted some new bots).
I aimed for my first solo gold medal and missed only 2 ranks (13 instead of 11) finally. It was a little bit disappointed. However I also realized many of the top bots (in gold regions) integrated my solution into theirs! And that made me really happy!
There are a few key takeaways from this competition that I found really valuable:
- Using vllm efficiently
- Stabilize LLM outputs using xml tags
- Finetuning LLAMA3 experience
- Realize the big gap improvement from LLAMA3 to LLAMA3.1
- A critical trick on the game (alpha trick) that disrupted the LB, and got understood by about 20 top teams, including mine.
- A brilliant 1st place solution from a new Kaggle superstar c-number. I like this solution so much! The below figures are the analysis made by him.
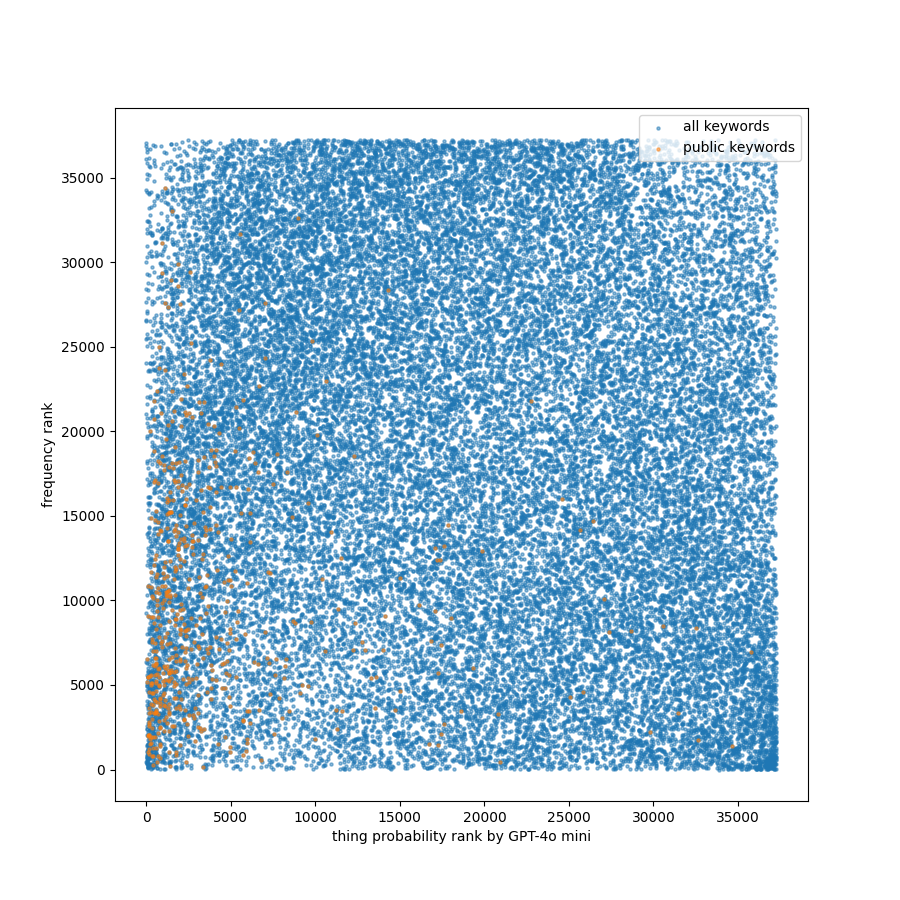
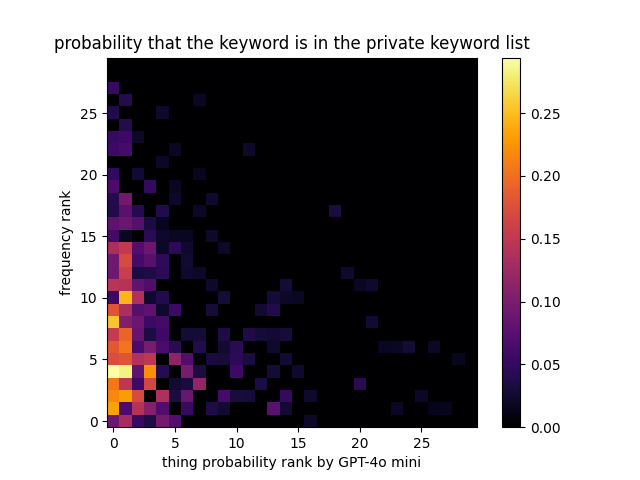
That’s it for a painstaking but wonderful Kaggle simulation competition.
Here is the link to my public Kaggle code, that has the top 5 most votes in the competition, and top 3 most forked (>200)! Many people used my code as the base solution and improve upon it. Note that the finetuning part was done offline, so the code is only about inferencing live on Kaggle mode.
The inference part (trained model loaded, shorten) also embedded below for viewer’s convenience. Thanks for reading and see you in another post!