(Rank 10/656) The power of DBSCAN -- an unsupervised clustering algorithm
by Kha Vo
Nothing can describe my feelings when I won my first Kaggle competition gold medal!
The most interesting fact about this feat is that it wasn’t a normal Kaggle competition then. We see almost >90% of the contests about supervised machine learning. This one is different.
It is the TrackML Particle Tracking Competition, and I finished at rank 10/656 (together with my great teammate Zidmie)
The difference is that due to the nature of the problem, traditional supervised ML algorithms don’t work well! Why? Let me explain the problem first.
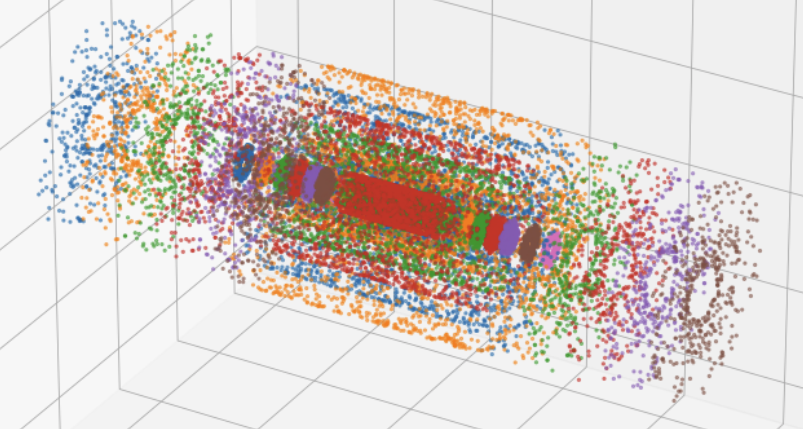
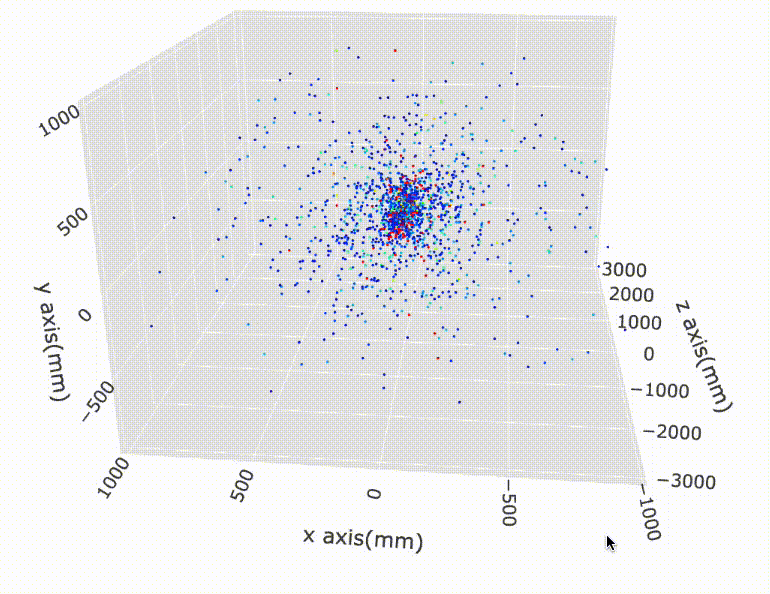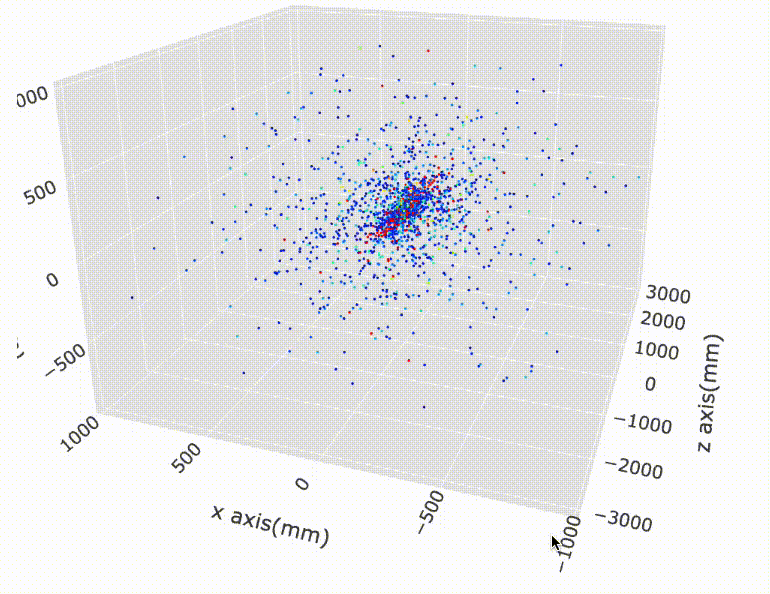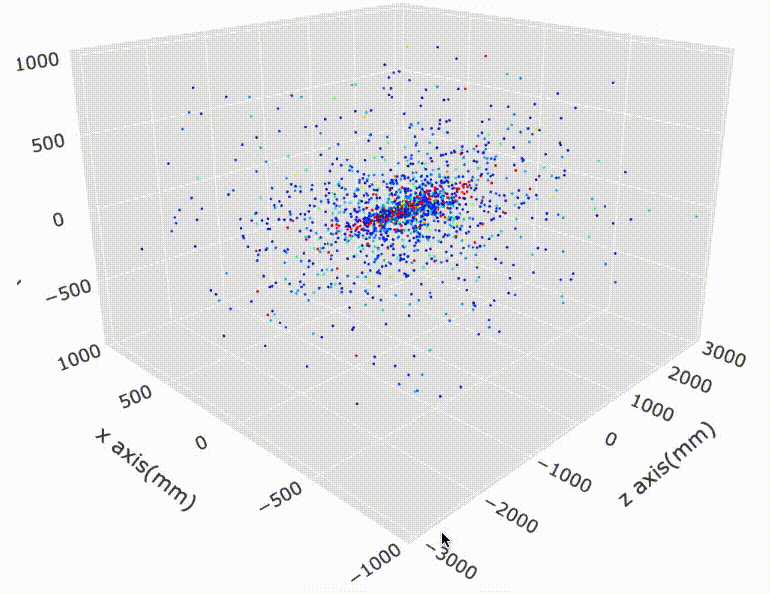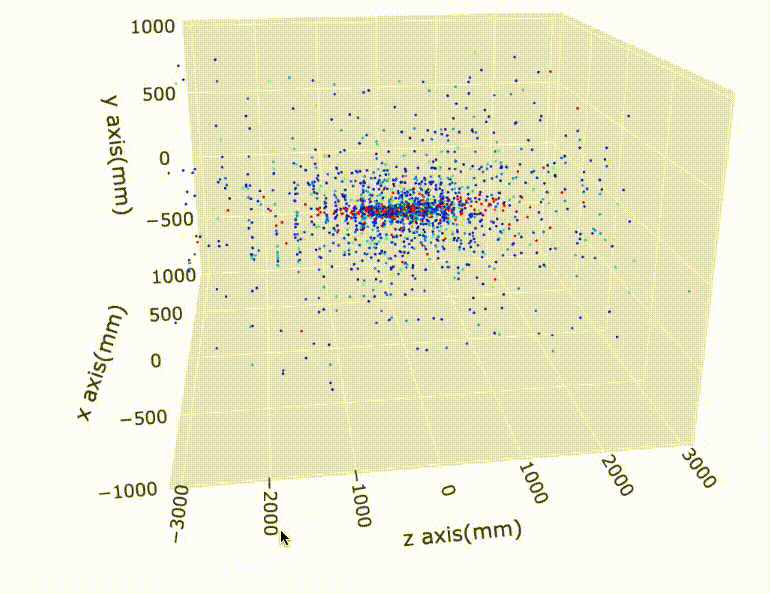
In this competition we are given a set of >8000 ‘events’. For each event, we are given about 100K ‘hits’ (or points) in 3D coordinates (x, y, z). So we know about every hit’s (x, y, z). These hits were the positions of the particles’ helix trajectories recorded inside a machine called the ‘detector’ in high-energy physics. So far so good?
In the detector, there are ‘layers’ and hits are only recorded when the particles hit these layers. So when they travel anywhere in the space between these layers, we don’t know where they are.
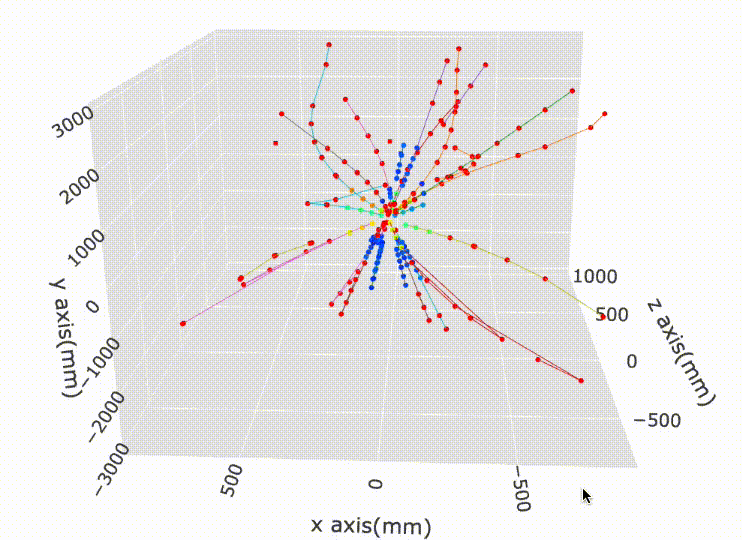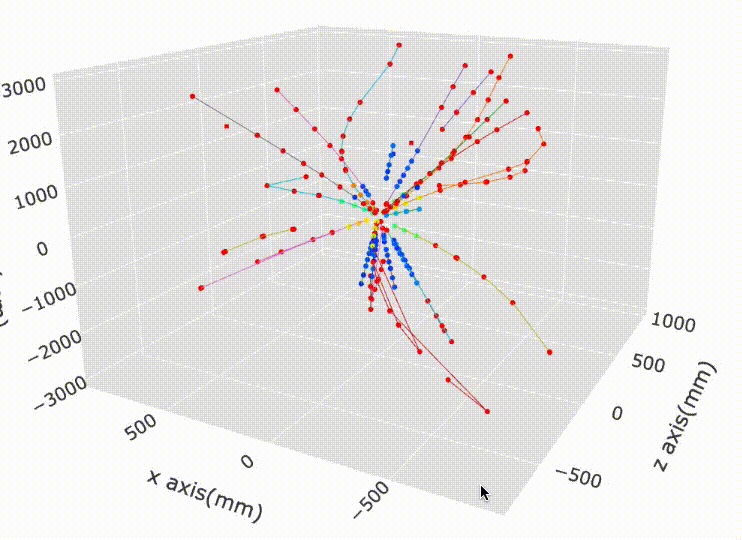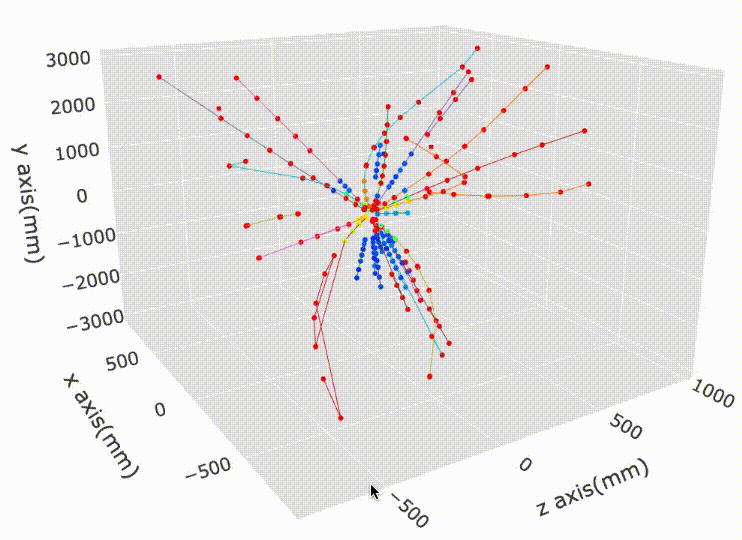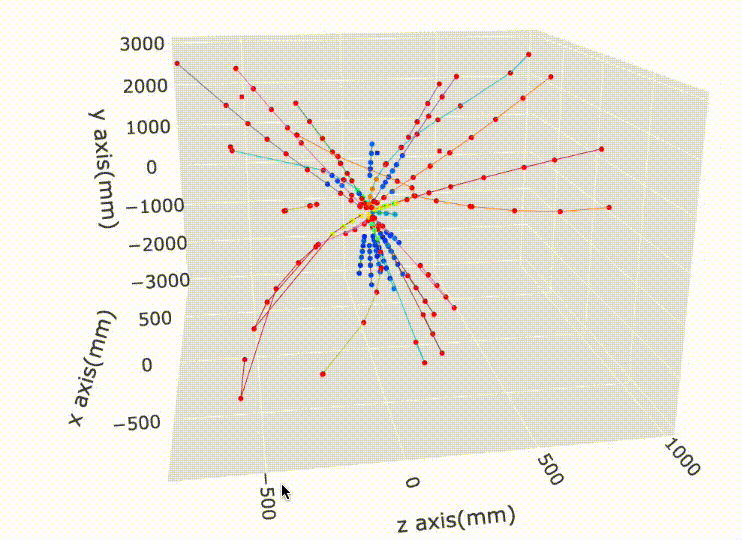
Imagine a single particle travels in a helix trajectory in space inside the detector. It will hit different layers (and continue to travel). So all of the positions of those hits are recorded. In other words, the total of 100K hits belong to many “trajectories” of single particles. We call this as ‘tracks’.
Let’s look some visualizations of all the hits inside the detector:
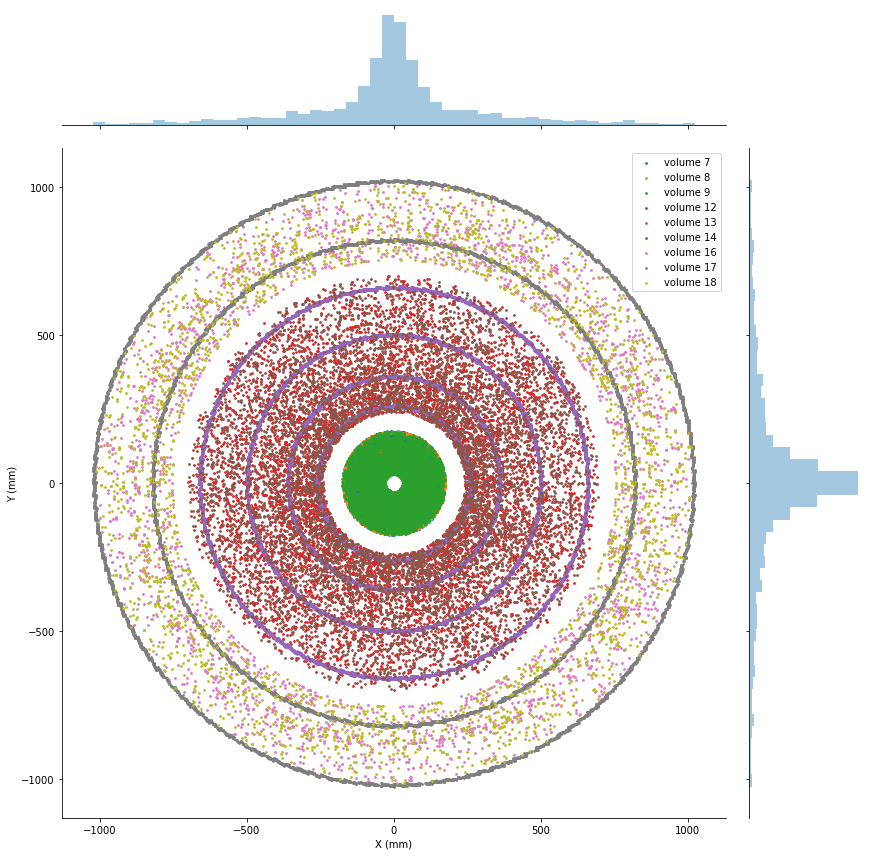
So, what’s the problem statement here?
We are required to reconstruct the ‘tracks’ from the hits alone! (of course, the labeled data is given, meaning that we have at hand a handful of events which we know which hits belong to which tracks).
Approaching this contest with a supervised machine learning method can be extremely challenging. The first evidence is that out of the top 10 teams, there is only 1 team (2nd place) employed a supervised ML approach with an NN architecture.
Why? That’s because we have the prior knowledge about the trajectories of the tracks: they’re all helices! If this is scientifically sounding, why don’t we exploit this fact?
Extracting some simple features, i.e., the Hough transforms, plugging them into an effective unsupervised algorithm, then voila! It worked like a charm!
I did experiments with many algos like kNN, HDBSCAN, EM… but finally DBSCAN is the best! It allows us to finetune parameters to adapt the the problem at hand. It’s fast, and it’s highly effective! I wrote a demo (simple version) Kaggle notebook to show off how I solve this competition.
It’s really unusual, and good to see a single unsupervised algorithm dominate a featured Kaggle competition with a very hard scientific problem. The world of AI is truly astounding and full of surprise!
Embedded below is my Kaggle version of the notebook (code), for viewer’s convenience. It only reflects about 50% of the full scale of the work.